Analysis for Genetic Programming Maze Rules
(You may wish to read the Analysis for Genetic Programming Maze Marchers before continuing.)
The Speed Problem: “Genetic Programming Maze Rules” runs considerably slower than Maze Marchers, because for Maze Marchers each codeturtle executes their code just once per generation, whereas in Maze Rules codeturtles execute their code each time step, to make a decision where to go. This is partially balanced by the fact that Maze Rules uses smaller program trees than Maze Marchers, but Maze Rules is still substantially slower. To help speed things up, I chose a smaller maximum generation limit for my experiments.
These are the default values used for the experiments, unless otherwise specified.
population-size = 50
initial-code-max-depth = 7
branch-chance = 0.5
clone-chance = 20
crossover-chance = 70
mutate-chance = 10
maze-file = "maze0.txt"
(fix-random-seed? = false for all
experiments, for obvious reasons)
|
|
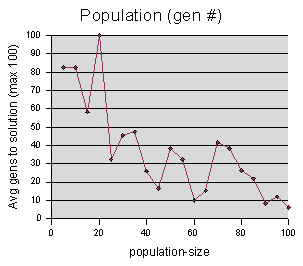
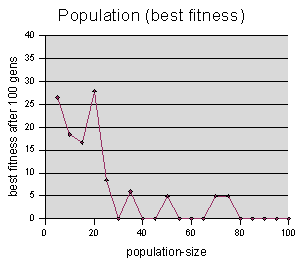
As expected, there is a benefit to increasing the population size.
I considered going on down the list of parameters, and varying them, just as I did with the Maze Marchers model. But I realized that looking at a lot of quasi-random graphs was not very interesting to me. The question that had been bothering me about this model, was whether or not genetic programming was effective at solving this maze rules problem at all. Certainly, it does create codeturtles that can solve the maze, but it often does seem quite out of the blue. Sometimes it creates a winner in the first or second generation. This suggests that genetic programming isn't really doing the work at all. |
 (Winning
codeturtle out of the blue...)
|
 |
 |
Let's start by working backwards. What does a winning program look like for our model? Here is a winning program, pulled straight off the back of a codeturtle sitting in the goal.
ifelse
not maze-wall-ahead? [
ifelse
not maze-wall-ahead? [
maze-turn-left
maze-turn-left
]
[
maze-turn-left
maze-turn-left
]
maze-turn-left
maze-turn-left
]
[
maze-turn-left
maze-turn-right
]
ifelse
maze-wall-left? [
ifelse
maze-wall-left? [
maze-turn-left
maze-turn-right
maze-turn-right
]
[
maze-turn-right
maze-turn-right
]
maze-turn-left
maze-turn-left
ifelse
maze-wall-right? [
maze-turn-right
maze-turn-right
]
[
maze-turn-right
]
]
[
maze-turn-left
ifelse
maze-wall-ahead? [
maze-turn-right
maze-turn-left
maze-turn-left
]
[
maze-turn-left
maze-turn-right
maze-turn-left
]
maze-turn-right
ifelse
not maze-wall-ahead? [
maze-turn-left
]
[
maze-turn-right
maze-turn-left
]
maze-turn-right
]
;;;
END OF CODE ;;;
At first sight, this beast seem hopelessly long and convoluted, but it turns out that we can reduce it by getting rid of redundant turning, and by applying a little logic, to the following:
ifelse
maze-wall-left? [
maze-turn-left
ifelse
maze-wall-right? [
maze-turn-right
]
[
]
maze-turn-right
]
[
maze-turn-left
]
If we write out what this code means in
English, we find that there are basically three situations that it
handles:
This is what is commonly referred to as “the right hand rule”. (In this case it is the left hand rule). The idea is that if you're starting on the perimeter of a maze, as long as you walk while keep your right hand touching the right wall beside you, you will find the exit (provided that it is also on the perimeter of the maze).
Well, it turns out that there isn't a lot of code there, after it has been boiled down. So when we're randomly generating programs that have very few statements to choose from, it isn't all that hard to come up with the right hand rule. That's why we get fairly good results with the random program generator.
Now the question is, if it's such an easy problem that we can randomly stumble upon a solution, then why doesn't genetic programming whip out a solution even more quickly? Well, go back up and look at the code of the winning codeturtle. What would happen if you changed any line of code? If you changed one of the redundant or useless pieces of the code, then your program's behavior would be exactly the same. And if you changed any of the useful lines of code, then your codeturtle would have completely different behavior, that in all likelihood won't get it anywhere near the finish. This disconnect between the fitness function and the code is the problem. That is, in order for genetic programming to work, we need turtles that have code that is close to the solution to have a high fitness value. Otherwise, all of the weighting and probabilities that go into choosing a new generation are meaningless. Genetic programming depends on the idea that there is some correlation, on average, between good code and good fitness. The correlation doesn't have to be perfect -- that's what all the randomness in Genetic Programming is for, to jump around past the places where the continuity isn't there. But if the correlation doesn't exist -- if our fitness function is selecting out bad turtles just as often as it is selecting out good turtles, then we may as well be using random search. (Note that for most problems of value, random search has only an infinitesimal chance of finding a solution).
We've answered the question of why genetic programming doesn't do any better than random search. Now let's conjecture on why it might be doing worse.
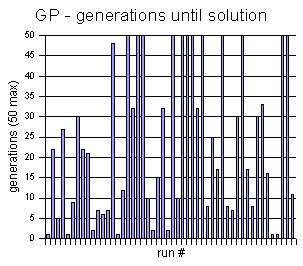
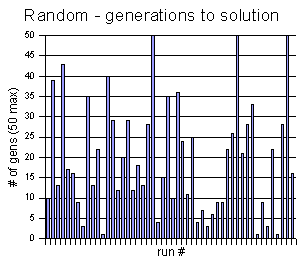
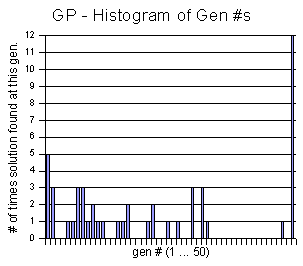
From the GP vs. Random experiment above, I created these two histogram charts, showing the frequency of each generation being the winning generation.
 |
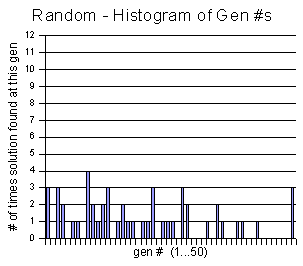 |
I think it is interesting to notice that
in the GP histogram, once it gets past generation 30 or so,
there is some white space. It seems to be little hope of finding
the solution after this point (most of them
end up at generation 50 and fail). I believe that the codeturtles
may be getting stuck in some sort of local minimum. That is, some of
the turtles
found a strategy that gave them a higher fitness than the others. This
caused their DNA to be propagated throughout the whole
population (perhaps slowly), and the massive inbreeding left the
codeturtles' code with a structure that was different enough from the
right hand rule that it was unlikely for crossover to create it. It
is always possible for a mutation to occur, which might create a
winner, too, but mutation was only occurring 10% of the time. Also,
every time cloning occurs (20% of the time), this means that the
exact same codeturtle will be in the new generation as was in the old
one. Since we already know that this codeturtle doesn't work, this
means that roughly 20% of each generation is being tested again. That
means that if the fitness function really isn't doing anything
to help move toward the solution, then it follows that genetic
programming would perform at least 20% worse than random search.
(Interestingly enough, my experiment testing against randomness found
genetic programming to be about 19% slower, but I hesitate to place
any significance on this.)
In conclusion, since it appears that
genetic programming is a poor choice for solving this problem, I
consider further analysis to be rather fruitless. The time would
be better spent on analysing a problem which genetic programming solves
particularly well. I believe that genetic programming performs
decently on the Maze Marchers model, although I have not run
experiments to compare it with random. (My belief is founded in
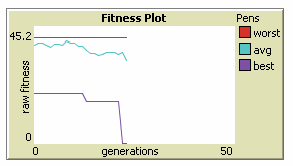
watching the model progress -- I see the code turtles clustering
somewhat on the pathways towards the goal, and also on the relatively
steady descent of the average and best fitness plots.)
Back to Forrest's Final Project Page.