Our Method
For our corpus, we are using a collection of 1,037 scripted scenes (which contain both spoken
text and accompanying animations) from the popular
Half-Life 2 computer game, which is based on the
Source
game engine. Within these scenes, 234 distinct animations appear.
We implemented a naive Bayesian classifier,
and we trained it on our corpus to learn which animations
occur with which words. In addition to providing our
classifier with single words or multi-word sequences (n-grams) from the
text that is spoken, we also experimented with
using more general features that we extracted from the text.
Two features we explored were the emotional valence of the words
(that is, how "negative" or "positive" a word is considered to
be), and the part-of-speech classification (noun, verb, adjective) of each word.
The goal of the classifier is, given some text, to assign an appropriate set of gestures to
that text. The timing of the animations is a further consideration, which we leave
for future work.
|
|
Cross-Validation Results
We took two approaches to the evaluation of our classifier.
The first approach was analytical, using 10-fold cross-validation on our dataset.
We measured success in the following way. Each scene has some set of animations attached
to it that were chosen by the original animators. If our classifier assigned some non-empty
subset of these animations to the scene, then we counted the scene as having been classified
correctly. We did not award any partial credit for near matches.
Our classifier, even using the best choice for features (which turned out to be tri-grams),
scored only 24.7% accuracy on this test. This is compared to the baseline of always
choosing the most common gesture (a subtle body-lean-forward animation), which scored 24%, because it
is used commonly as an accent in combination with other animations (evidently in 24% of the scenes!).
With this metric, our classifier's performance appears very poor, but we noticed that the scenes that we generated with our
classifier looked reasonable (much more reasonable than always choosing the same animation,
which quickly becomes repetitive). We concluded that this metric of success was not a
very useful one for us. What really matters is whether the
gestures that we assign look natural to human viewers, so we performed a user study.
User Study Results
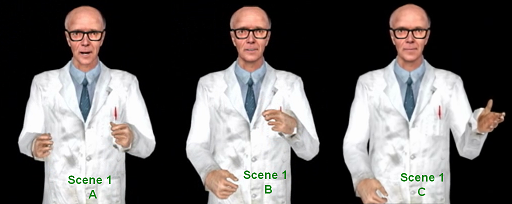
We generated three versions of 10 randomly chosen single-gesture scenes, where one version contained the original gesture,
one contained our classifier's gesture, and one contained a randomly chosen gesture.
We had 20 subjects watch this video, and rank the three versions from "most applicable gesture" to "least applicable gesture".
User Study - Scene Comparison
|
|
Caption: Twenty subjects were asked to rank three variants of each scene, which allowed us to compare our classifier's performance against the original gestures and also against randomly chosen gestures.
|
From this, we accumulated 200 preference rankings (from 20 subjects each watching 10 scenes).
Our classifier's gesture beat the random gesture 56% of the time, and it beat the the original gesture 25% of the time.
On the one hand, these numbers suggest that we are doing only mildly better than random.
On the other hand, they suggest that 25% of the time, our gestures are at least indistinguishable
in quality from the original animators, so the classifier's performance isn't bad.
Perhaps the important take-away message from this study is that many different gestures
may appear equally natural given the same spoken text.
Sample Video
Last but not least, here is a sample video that showcases how our classifier assigned gestures
to a typical scene.
|
Sample Video
|
|
Caption: The body gestures shown in this scene were assigned by our classifier (trained on a combination of bi-grams and unigrams). Facial muscle movements are those assigned by the original animators.
Requires Windows Media Player & ActiveX
If you are experiencing problems viewing in the web page, then download here
|
For the interested reader, the full details about Project GestureMap may be found in our paper:
Learning to Gesticulate: Applying Appropriate Animations to Spoken Text
|
 Watch the comparison video used in this study
Watch the comparison video used in this study